Arrays and Lists
Efficiently working with tables can be difficult. Let's learn about the tools Fusion provides to make working with arrays and tables easier.
Required code
1 2 3 4 5 6 7 | |
Computed Arrays¶
Suppose we have a state object storing an array of numbers, and we'd like to create a computed object which doubles each number. You could achieve this with a for-pairs loop:
7 8 9 10 11 12 13 14 15 16 17 | |
While this works, it's pretty verbose. To make this code simpler, Fusion has a
special computed object designed for processing tables, known as ComputedPairs.
To use it, we need to import ComputedPairs from Fusion:
1 2 3 4 5 6 | |
ComputedPairs acts similarly to the for-pairs loop we wrote above - it goes
through each entry of the array, processes the value, and saves it into the
new array:
8 9 10 11 12 13 14 | |
This can be used to process any kind of table, not just arrays. Notice how the keys stay the same, and the value is whatever you return:
8 9 10 11 12 13 14 | |
Cleaning Up Values¶
Sometimes, you might use ComputedPairs to generate lists of instances, or
other similar data types. When we're done with these, we need to destroy them.
Conveniently, ComputedPairs already cleans up some types when they're removed
from the output array:
- returned instances will be destroyed
- returned event connections will be disconnected
- returned functions will be run
- returned objects will have their
:Destroy()or:destroy()methods called - returned arrays will have their contents cleaned up
This should cover most use cases by default. However, if you need to override
this cleanup behaviour, you can pass in an optional destructor function as
the second argument. It will be called any time a generated value is removed or
overwritten, so you can clean it up:
8 9 10 11 12 13 14 15 16 17 18 19 20 | |
Removed: Hello, Dave
Removed: Hello, Sebastian
Optimisation¶
To improve performance, ComputedPairs doesn't recalculate a key if its value
stays the same:
8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |
Creating processedData...
...recalculating key: One
...recalculating key: Two
...recalculating key: Three
Changing the values of some keys...
...recalculating key: Two
...recalculating key: Four
Because the keys Two and Four have different values after the change,
they're recalculated. However, One and Three have the same values, so
they'll be reused instead:
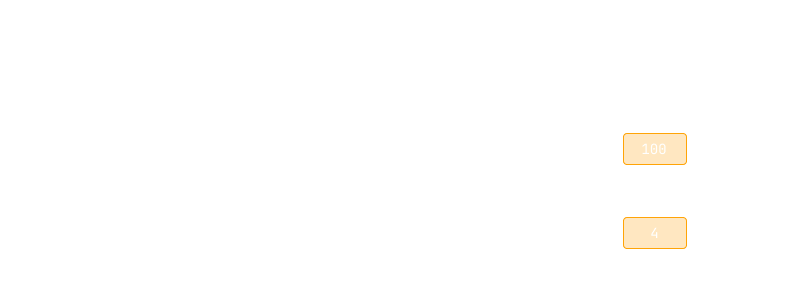
This is a simple rule which should work well for tables with 'stable keys' (keys that don't change as other values are added and removed).
However, if you're working with 'unstable keys' (e.g. an array where values can
move to different keys) then you can get unnecessary recalculations. In the
following code, Yellow gets recalculated, because it moves to a different key:
8 9 10 11 12 13 14 15 16 17 18 | |
Creating processedData...
...recalculating key: 1 value: Red
...recalculating key: 2 value: Green
...recalculating key: 3 value: Blue
...recalculating key: 4 value: Yellow
Moving the values around...
...recalculating key: 3 value: Yellow
You can see this more clearly in the following diagram - the value of key 3 was changed, so it triggered a recalculation:
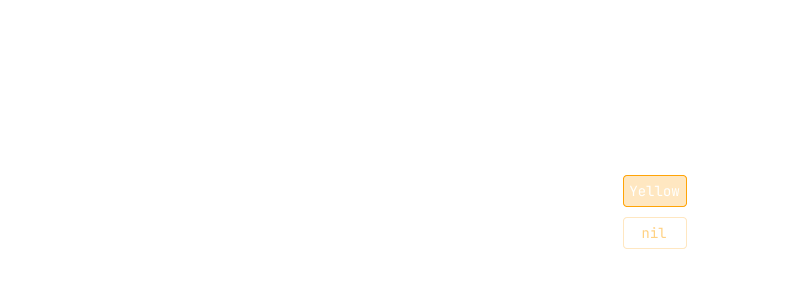
If the keys aren't needed, you can use your values as keys instead. This makes them stable, because they won't be affected by other insertions or removals:
8 9 10 11 12 13 14 15 16 17 18 | |
Creating processedData...
...recalculating key: Red
...recalculating key: Green
...recalculating key: Blue
...recalculating key: Yellow
Removing Blue...
Notice that, when we remove Blue, no other values are recalculated. This is
ideal, and means we're not doing unnecessary processing:
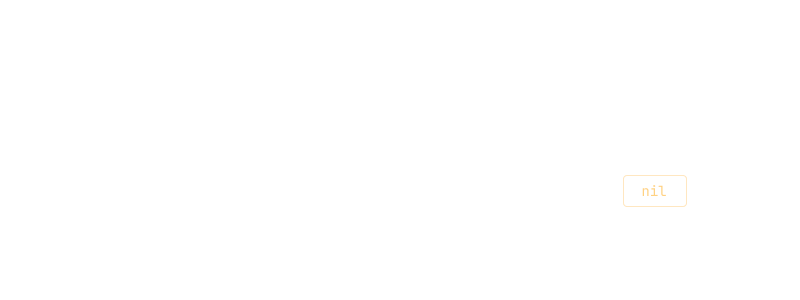
This is especially important when optimising 'heavy' arrays, for example long lists of instances. The less unnecessary recalculation, the better!
With that, you should now have a basic idea of how to work with table state in Fusion. When you get used to this workflow, you can express your logic cleanly, and get great caching and cleanup behaviour for free.
Finished code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |